Introduction
What motivates system optimization? Often, it is the arrival of new customer demands: a higher throughput requirement, a tighter latency target, or a new use case that pushes a system beyond its original specifications. In short, the need for optimization begins when an existing system is unable to adapt to new expectations. The task can then be split into two parts: first, to comprehend the current design constraints; and second, to determine what it would take to adapt.
Step 1 : Comprehension – The Why
Why is the current system unable to satisfy the performance specification? The first step is to analyze the design through the lens of requirements — to understand how various use cases impact resource utilization such as CPU cycles, storage bandwidth, or memory footprint etc. Such analysis provides insights and hypotheses about possible systemic imbalances. By modeling use cases and capturing performance metrics, these hypotheses can be validated or refined. Depending on the scale and complexity of the system, isolating the bottleneck may require iterations. Still, measurement is vital to confirming assumptions and deriving solutions.
Step 2 : Solutions – The How
The details of the bottleneck identified through measurements form the input to the next step — identifying a solution. Captured data should highlight which resources are heavily utilized (ie: expensive) and which remain relatively idle. The goal is to target these imbalances at the architectural, algorithmic, or design level. In other words, every subsystem should be efficiently utilized throughout the execution of a use case. This balancing act typically involves either reducing contention or introducing greater concurrency. Contention can be reduced by optimizing algorithms, adding caches, batching operations, or improving prioritization. Concurrency, on the other hand, often requires reworking the pipeline.
Practicing What We Preach
The following real-world industry examples illustrate how this methodology can be applied in practice. It also explains the challenges that arise when theory meets practice in projects of different scales and complexities.
Asynchronous Raw NAND Writes
Similar to how branch prediction and multi-issue execution keeps CPU pipelines busy, concurrency can be applied at every layer of a computing system to ensure efficient resource usage. One such example came from NAND flash file system throughput improvement. Here customer demanded 50-60% improvement in write throughput. The existing design was simple and effective, until Samsung determined it was inadequate for their next generation of feature phones.
Step 1 : Original Design
As shown below (Fig 1), all components executed sequentially.

In a resource-constrained RTOS environment, this simplicity had its benefits. But with a new performance specification, this became the limitation.
End to end latency was around 400μs, of which 250μs was spent by CPU waiting on NAND programming. In effect, the CPU — running application and file system — was idle majority of the time. Measurements identified the bottleneck — Step 1 completed.
Step 2 : Improved Design – Concurrency
Fig2 below shows the new architecture. Since the bottleneck was obvious, the solution was to introduce concurrency between CPU and Raw NAND by making that lowest level programming interface asynchronous. Alternative solutions like asynchronous I/O at higher file system or application level would have been more expensive and likely much less effective. Because they all can create resource contentions down the stack.

A Cache
Introducing a simple cache allowed NAND programming to be decoupled from rest of the sequence. File system will now just update the cache, while the actual programming of NAND happens in the background. This allowed both CPU and NAND to execute concurrently.
- Throughput improvement: >70%
- Trade-offs: additional memory usage and an acceptable increase in system complexity
While conceptually simple, the implementation within a memory-constrained RTOS raised interesting challenges. Cache memory management had to be carefully tuned for efficiency, and NAND bad block management had to be performed asynchronously. These intricacies led to an interesting debate on patentability and an eventual grant.
The Verdict
Illustrates how the two step methodology delivered results and even an intellectual property. Next example applies these same principles within a more complex environment with similar results.
Linux File System Optimization
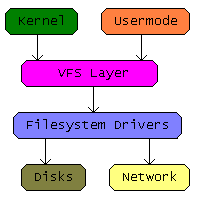
The requirement here was to maximize streaming read/write throughput for a proprietary file system — ideally outperforming native solutions like Ext4 and UBIFS. This project required running a benchmark such as IOZone and iteratively isolating bottlenecks across the storage stack. The simplified architecture diagram (Fig 3) highlights the critical paths uncovered by measurement. (See more design details about Linux Storage Stack in this link)
Step 1 : Design Resource Contentions

Two major bottlenecks were identified through design review and measurements:
-
File System Contention — Multiple applications accessing the file system introduced latencies in the tens of microseconds.
-
Block Driver Contention — Concurrent access from the file system and page cache to the block device caused latencies up to the order of single-digit seconds.
Page cache is essentially data cache from file system user perspective, while block Driver is basically storage device management layer which abstracts disk I/O functions.
Step 2: Caches
File System Contention Resolution
During streaming I/O, the primary role of a file system in Linux is to map file offset to storage block addresses. Concurrent access from multiple processes to the file system for this mapping operation became a source of contention. Optimizing the file system mapping algorithm itself would be expensive, so the solution was to prefetch and cache the mapping data at higher VFS layer.
To minimize overhead, prefetching was triggered only when streaming I/O was detected — essentially repeated reads or writes to contiguous offsets. This cache effectively reduced latency from tens of microseconds to ~5 μs on average.
Block Driver Contention Resolution
Several strategies could have resolved this — optimizing file system or application, increasing page cache memory, or adding dedicated storage paths for these relatively independent access streams. But the solution employed was much more targeted and simpler:
- Increase the in-memory cache for file system metadata.
- Disable automatic file system metadata syncs, instead rely on background sync that executed only when file system was idle.

Now during peak I/O activity, block driver was practically dedicated to service page cache requests. Metadata syncs were also deferred to idle time windows. This combination of hierarchical caching and careful prioritization resolved the block driver bottleneck.
The trade-offs were cache management overhead, increase in memory footprint, and some risk in loss of data due to deferred background syncs. File system itself was power fail safe so it’s guaranteed to work across power failures, but the last written file contents before a metadata sync could be lost. All these were acceptable from customer’s use case perspective.
The Verdict
Identification of bottlenecks was possible only by layering metrics across the stack — from application level down to block driver. Then executing customer workloads, and then analyzing correlating spikes across time.
The solutions were then targeted to resolve specific resource contentions with minimal impact to other use cases. Even within a relatively complex stack like Linux kernel, the two step methodology of comprehension and then problem solving was effective.
While the Linux FS project tackled performance inside a single device, the next example scales up to cloud infrastructure, where data pipelines process gigabytes of metrics across distributed systems.
AWS Data Pipeline
The requirement here was to collect gigabytes of metrics from a test network, then process and monitor them for key performance indicators. These metrics were generated by the verification target — a cloud storage transport protocol (SRD) which was still under development. The project goal was to design a system to extract, transform, and load end-to-end test metrics from this storage stack.
Because the storage stack under test was experimental, the requirements for data transformation were open-ended. Debugging relied on running SQL queries and looking for correlations in collected metrics to isolate bottlenecks. The expectation was to support a wide range of queries with “reasonable” latency, despite little clarity on the specific use cases.
Open-Ended Requirements
The experimental nature of this project imposed three constraints:
- Quick project execution due to tight timelines
- A simple, adaptable architecture to handle unknown future use cases.
- Low latency access to stored data for interactive debug.
Step 1 : Data Lake and S3 Measurements
After evaluating multiple solutions, AWS S3, an unstructured data storage was chosen as the database backend. Compared to traditional databases, it offered lower maintenance overhead and schema flexibility. Even though a simple object store, when used to save structured files like JSON or CSV, it can act as a database backend to services like AWS Athena and Redshift Spectrum. But, the drawback was performance: throughput fell below 1 MB/sec when accessing large numbers of small files. Measurements identified this as the primary bottleneck.
Step 2 : Partitions and ETL Chains
Partitioning
Partitioning was the first aspect to the solution. As AWS notes :
By partitioning your data, you can restrict the amount of data scanned by downstream analytics engines, thereby improving performance and reducing the cost for queries.
Files corresponding to a single day’s worth of data are placed under a prefix such as
s3://my_bucket/logs/year=2022/month=06/day=01/. We can use a WHERE clause to query the data as follows: "SELECT * FROM table WHERE year=2023 AND month=06 AND day=01"
The preceding query reads only the data inside the partition folder year=2022/month=06/day=01 instead of scanning through the files under all partitions
With partitioning and by limiting SQL query ranges, access complexity dropped to O(Log n) from O(n) (see below Fig 5).

Data Lake ETL Chains
Initially, data was stored with year/month/day partition. This was later extracted and transformed using AWS Athena. Filtered output was redirected in CSV form into another partitioned S3 bucket for further queries and debug.
For example :
Output of a query like “”SELECT * FROM table WHERE year=2023 AND month=06 AND day=01 AND server_type=”storage”“” was redirected to location s3://my_bucket/logs/server_type=storage/
This created chained and tailored datasets for detailed analysis — in above case storage server metrics.
Depending on emerging requirements, these ETL chains were developed, and this allowed for simple scalable organization of large scale data.
The Verdict
The two-step methodology applied here was:
-
Identify — Small file access on S3 was measured and confirmed as the bottleneck.
-
Resolve — Partitioning and ETL chaining were introduced to limit query scope and improve throughput.
Despite relying on a low-cost S3 backend, the system achieved acceptable query latencies for debugging, while remaining flexible enough to handle evolving requirements. This combination of simplicity and scalability allowed gigabytes of test data to be managed efficiently under aggressive development timelines.
Example proved the two step works at gigabyte scale, next illustration dials it down to kilobytes level, shows how the same principle can work on a wearable embedded device.
Noisy Neighbor
The problem here was data loss on shared diagnostic channels running on a resource-constrained wearable device (in this case, the now discontinued Amazon Halo). Diagnostic in this case involved logs, metrics and other critical information required to assess general health of the device. So, several components used these channels, and it was difficult to pinpoint the “noisy neighbor” causing these drops. Usual solutions of enforcing a per-component quota would have been too expensive in terms of complexity and overhead.
Following the two-step method, the first step in this case would be to instrument metrics to monitor bandwidth usage and gain a clear understanding of the problem.
Step 1 : Instrument Usage Metrics
Instrumented metrics tracked :
- Min/Maximum/Average bandwidth utilization
- Dropped byte count.
First three metrics monitored overall trends, while dropped bytes highlighted actual data loss. Plotting dropped bytes across time allowed easy identification of relevant time windows.

Correlation & Cross-correlation
Focusing on logs or metrics captured during dropped bytes intervals like 12:05 or 12:20 helped narrow down:
-
What was happening (the active use case)
-
Who was involved (the specific component)
For example : Correlating a spike at 12:05 with actual logs conveyed eMMC or FAT32 as likely culprits. Investigating the code path related to eMMC error handling helped further isolate the reason.
- [12:01][1233][INFO][FAT32]File opened
- [12:02][1234][INFO][FAT32]Reading LBA 20
- [12:02][1235][INFO][eMMC]Device read initated
- [12:03][1236][ERROR][eMMC] Error interrupt
- [12:03][1237][ERROR][eMMC] CRC error detected
- [12:03][1238][ERROR][eMMC] Unrecoverable error returned
- [12:07][1249][ERROR][FAT32] Directory entry read failed
When multiple diagnostic channels exist — for example, logs and metrics — cross-correlation can be even more powerful. By examining related metrics during a log drop window (or vice versa), you can triangulate the root cause with higher confidence.
Step 2 : Resolution through Prioritization
Once the noisy culprits are identified, the responsibility was now on the component or use case designer to prioritize and reduce the usage.
Final question was — why is dropped_bytes metric itself never dropped.
- First, it’s a low frequency, aggregated metric.
- Second, it’s reported through low priority idle task. This prioritization ensured bandwidth is always available for it.
Unlike timing sensitive inline metrics like errors or warnings, these aggregate values can be safely prioritized lower. This design guarantees accurate reporting of overall system health without impacting inline real-time reported diagnostics.
The Verdict
Once again, the two-step methodology proved effective:
-
Identify by measuring and correlating metrics to isolate the noisy neighbor.
-
Resolve by fixing noisy element and by introducing prioritization within telemetry.
While this example applied noisy neighbor within an embedded device, next illustration will explain how these same principles can be applied at slightly bigger scale for memory optimization.
Dynamic Memory Allocation
The goal here was to reduce Linux DRAM footprint on Amazon Alexa. As expected, initial measurements indicated kernel footprint was relatively small compared to user-space. With approximately 200 runtime processes, getting the overall measurements itself seemed like a complex task.
Step 1 : The Haystack – Capturing data
With high number of concurrent processes, the measurement itself demanded a methodical approach. Approach used was a combination of Linux pmap and python scripting.
PMAP and Python Pandas
Linux provides a useful tool named pmap, this provides memory map for a process. With 200 processes, there will be 200 such maps with detailed information like size, permissions, and segment type (e.g., library, stack, or [anon] for dynamically allocated memory).
Example below:
12345: /usr/bin/my_applicationAddress Kbytes RSS Dirty Mode Mapping0000555a297b6000 12 8 0 r-x-- /usr/bin/my_application0000555a297b9000 4 4 4 r---- /usr/bin/my_application0000555a297ba000 4 4 4 rw--- /usr/bin/my_application0000555a297bb000 64 64 64 rw--- [ anon ]00007f9c87d46000 1864 1024 0 r-x-- /usr/lib/x86_64-linux-gnu/libc-2.31.so00007f9c87f18000 512 64 0 r---- /usr/lib/x86_64-linux-gnu/libc-2.31.so00007f9c87f98000 16 16 16 rw--- /usr/lib/x86_64-linux-gnu/libc-2.31.so00007f9c87f9c000 20 20 20 rw--- [ anon ]00007f9c87fa1000 144 144 0 r-x-- /usr/lib/x86_64-linux-gnu/ld-2.31.so00007f9c87fc5000 8 8 8 r---- /usr/lib/x86_64-linux-gnu/ld-2.31.so00007f9c87fc7000 4 4 4 rw--- /usr/lib/x86_64-linux-gnu/ld-2.31.so00007f9c87fc8000 4 4 4 rw--- [ anon ]00007f9c87fca000 8192 8192 8192 rw--- [ anon ]00007ffc12345000 132 12 0 rw--- [ stack ]The output of pmap roughly resembles space delimited CSV, so some simple scripting could clean this up, transform into comma delimited form and then load it into a Pandas Dataframe.
A union of 200 such tables correlating to each process provided the unified view of the whole system. Now some SQL queries to slice, filter, and aggregate provided different insights into system-wide memory distribution.
Step 2 : Finding The Needle
Grouping rows in the unified table based on different types of memory maps indicated [anon] (ie: dynamic allocation) as the bottleneck. Studying the output stats of Android Native Memory allocator showed some internal fragmentation. Diving a bit deeper and investigating available memory config led to the discovery of MALLOC_SVELTE option. Setting this to true enables low-memory configuration.
MALLOC_SVELTE := true
Similar to the usual CPU/memory trade-off cases, even here enabling this can impact allocation latency. But it also expected to improve memory utilization and is meant for memory constrained systems. Measurements indicated ~30% reduction in memory footprint with some hit in latency for a subset of products.
The Verdict
Measurements led to identifying the exact bottleneck — with that a clear targeted solution with highest return on investment was discovered. This one line change to add an option reduced memory by a third. System successfully reconfigured for adapting to a memory constrained environment. In this particular case, measurement itself was the challenge and it required a bit of cross-disciplinary approach — applying of some big data concepts to Linux system optimization.
The Finale
Whether it’s an extinct feature phone, or modern data lakes, the same two step methodology delivers results. It works because it mirrors the scientific method: observe, hypothesize, test, refine. Applying this to real-world systems demand some creativity and a degree of patience. And even when it doesn’t fully deliver results, it leaves us with defensible measurements that explain why—and a clearer picture of where to look next.










{kind=link}