Linux Content Index
— File System Architecture – Part I
–– File System Architecture– Part II
–– File System Write
–– Buffer Cache
–– Storage Cache
Linux file write methodology is specific to particular file systems. For example, JFFS2 will sync data within the user process ‘context’ itself (inside write_end call), while file systems like UBIFS, LogFS, Ext & FAT tends to create dirty pages and let the background flusher task manage the sync.
These two methodologies come with their own advantages, but usage of the second method leads to Linux kernel exhibiting certain quirks which might drastically impact the write throughput measurements.

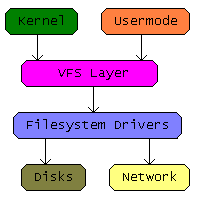
The above diagram does give an overview of the design, there are in fact two main attributes to this architecture:
COPY : User space data is copied into a kernel page associated with the file and marked as dirty via“write_begin” and “write_end” file system call backs, they are in fact invoked for every “write” system call made by the user process. So while they are indeed kernel mode functions they get executed on behalf of the user space process which in turn simply waits on the the system call. The sequence is illustrated below:
write_begin() /* Informs FS about the number of bytes being written */
mem_copy() /* Copies data to kernel page cache.*/
write_end() /* Copied kernel page marked as dirty and FS internal */
/* meta information is updated */
&
Write-Back : The Linux kernel will spawn a flusher task to write these above created dirty pages into the storage. For that this newly spawned task would typically invoke file system specific “writepage” or “writepages” call-back.
Some Nitty-Gritty Details
The call-backs mentioned above are specific to the file system and are essentially registered during its initialization with kernel. You might have noticed that the above design almost resemble a classic producer consumer scenario, but there are certain nuances:
Lower Threshold: The flusher task (consumer) is spawned only when a certain percentage of page cache becomes dirty. So there is indeed a lower threshold (configured in /proc/sys/vm/dirty_background_ratio) for spawning this task. Please note that it can also be invoked after an internal time-out. So even if the dirty pages are in small numbers, they are not kept around in volatile memory for a long time.
Higher Threshold: Once a certain high percentage of page cache is dirtied by a user process (producer), this process is forced to sleep to avoid the kernel running out of memory. Such a user process is not unhooked from this involuntary sleep until the flusher task catches up and brings down the dirty page levels to acceptable limits. This way kernel tends to push back on the process which comes with a massive capacity to write data. This higher threshold can be specified by writing to /proc/sys/vm/dirty_ratio.
So between the above mentioned lower and upper thresholds the system tends to have two concurrent tasks, one which dirty the pages with contents and the other which cleans them up with a write back. If there are too many dirty pages being created, then Linux might also spawn multiple flusher tasks. Seems like this design might scale well on SMP architectures with multiple storage disk paths.
We could bring some more clarity with the exposition of code level details. The critical aspect of the above mechanism is implemented in the below mentioned balance_dirty_pages (page-writeback.c) which gets invoked after “write_end” call inside kernel.
The function audits the number of dirty pages in the system and then decides whether the user process should be stalled.
static void balance_dirty_pages (struct address_space *mapping, unsigned long write_chunk)
{
int pause = 1;
…
……
………
for (;;)
{
….
…… /* Code checks for dirty page status and breaks out of the loop only if the dirty page ratio has gone down */
……..
io_schedule_timeout(pause);
/*
* Increase the delay for each loop, up to our previous
* default of taking a 100ms nap.
*/
pause <<= 1; if (pause > HZ / 10)
pause = HZ / 10;
}
}
The argument ‘pause’ to the function io_schedule_timeout specify the sleep time in terms of jiffies while the big for (;;) loop repeatedly checks the dirty page ratio after each sleep cycle and if there is no ample reduction in that then the sleep time is doubled until it reaches 100mS, which is in fact the maximum time the ‘producer‘ process can be forced to sleep. This algorithm is executed during file writes to ensure that no rogue process goes amok consuming the full page cache memory.
The Gist
We can attribute considerable significance for the above mentioned upper and lower thresholds, if they are not fine tuned for the system specific use cases then the RAM utilization will be far from optimal. The particulars for these configurations will depend on RAM size plus how many processes will concurrently initiate file system writes, how big these writes will be, file sizes being written, typical time intervals between successive file writes etc.
A file system mounted with syncs off is meant to utilize page cache for buffering. Optimal write speeds will mandate that the upper threshold be large enough to buffer the full file while allowing seamless concurrent write backs, otherwise the kernel response time for user process writes will be erratic at best.
Another critical aspect is that the writepage should have minimal interference with write_begin & write_end, only then the flusher task write backs can happen with least friction with regards to the user process which is constantly invoking the latter two functions. If they share some resource, then eventually the user process and the flusher task will end up waiting on each other and the expected quick response time of an asynchronous buffered page cache write will not be materialized.











{kind=link}