Linux Content Index
— File System Architecture – Part I
–– File System Architecture– Part II
–– File System Write
–– Buffer Cache
–– Linux File Write
Every system use case involves a combination of software modules talking to each other. But an optimal system is more than set of efficient modules. The overall architectural arrangement of these modules and their data/control interfaces also impacts the performance. In that sense, several useful design methodologies can be observed from examining the storage sub system within Linux.

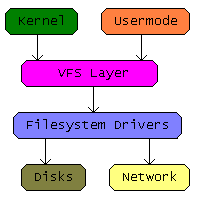
Various abstraction layers have their own purpose. For example, VFS exposes a uniform interface to the user applications, while it’s the file system which actually implements the structural representation of files within the device. Eventually, how each storage sector is accessed will depend on the block driver interactions with the hardware. Productivity depends on how quickly a system can service user requests. In other words, the response time is critical. The pure logic implemented for each of the involved modules could be efficient, but if they are merely stacked up vertically then it will be only as good as using a primitive processor with no internal caches or pipelined executions.
*********************************
Inode-Dentry Cache
Book keeping information associated with each file is represented by two kernel structures — Inodes and Dentries. In bare simple terms these constructs hold the information necessary to identify and locate the storage blocks associated with a file. A multitasking environment might have numerous processes accessing the same volume or even the same file. Caching this information at higher levels can reduce contentions associated with the corresponding lower layers. If the repeated file accesses would be picked from the VFS cache, then the file system will be free to quickly service the new requests. Consider a use case where there are multiple processes looking up for a file in different dedicated directories; without a cache, the contention on the file system will scale with the number of processes. But with a good cache mechanism, only the brand new requests would end up accessing the file system module. The idea is quite like a fully associative hierarchical hardware cache.

*********************************
Data Cache
Inodes and Dentries are accessed by the kernel to eventually locate the file contents, hence the above cache is only a part of the solution while the data cache handles the rest (see below Fig -3). Even here we need frequently accessed file data to be cached and only the new writes or new reads should end up contending for file system module attention. Please note that inside the kernel, the pages associated with file are arranged as a radix tree indexed via file offsets. While the dentry cache is managed by a hash table. Also, each such data cache is eventually associated with the corresponding Inode.
Cache mechanism also determines the program execution speed, it’s closely related to how efficiently the binary sections of the executable are managed within the RAM. For example, the read-ahead heuristics would determine how often the system endures an executable page miss. Also another useful illustration of the utility of a cache is the use case where a program is accessing files from the same volume where its executable is paging from; without a cache the contention on the file system module would be tremendous.

*********************************
Cache Management
Cache management involves its own complexities. How these buffers are filled, flushed, invalidated or marked as dirty depends on the file system module. Linux kernel merely invokes the file system registered call-backs and expects that the associated cache buffers would be handled accordingly. For example, during a file overwrite the file system should mark the overwritten cached page as dirty, otherwise the flush may never get invoked for that page.
We can also state that the Linux kernel VFS abstracts the pure logic of how data is represented on the storage device from how it’s viewed by kernel on a running system. In this manner the role of the file system is limited to its core functionality of mapping file access to actual storage blocks and it also deals with the transformation between internal file system specific representation of files to the generic VFS Inode, Dentry and data cache constructs. Eventually, how file is created, deleted or modified and how the associated data cache is managed depends solely on the file system module.
For example, a new file creation would involve invoking of the file system module call-backs registered via kernel structure “inode_operations”. The lookup call-backs registered here would be employed to avoid file name duplication and also the obvious “create inode” call would be needed to create the file. An fopen would invoke “file_operations” callback and similarly a data read/write would involve use of “address_space_operations”.
How the registered file system call-backs would eventually manage the inode, dentry and the page data cache buffers would depend on its own inherent logic. So here there is a kind of loop where the VFS calls the file system module call-backs and those modules would in turn call other kernel helper functions to handle specific cache buffer operations like clean, flush, write-back etc. In the end when the file system call-backs return the control back to VFS the associated caches should be already configured and ready for use.

*********************************
Load Store Analogy
A generic Linux file system can be described as a module which directly services the kernel cache by implementing functions for creating, invalidating or flushing various cache entries and in this manner it only indirectly caters to the POSIX file operations. The methodology here is in a way analogous to how a RISC load-store would differ from a 8051 like CISC design, separation of the slow memory access from the register operations constitute the core attribute of a load-store mechanism. Here the Linux kernel ensures that the operations on the cache can happen in parallel with an ongoing load or store which might involve the file system and the driver modules, the obvious trade-offs are complexity and memory consumption.
*********************************
Pipelines
Caches are effective when there are read ahead mechanisms and background flusher tasks. A pipelined architecture would involve as much parallel execution as possible. Cache memories are filled in advance by the reader threads while the dirty entries are constantly flushed in the background by worker threads. Such sector I/O requests are asynchronously queued and processed by the block driver task which will eventually DMA them into the interfaced device. After the writes, the corresponding cache entries are marked as clean and similarly after the reads the entries are marked as up-to-date. The pipeline stages can be seen in the below Fig 5.

System organization evolves over time when various use cases are analyzed for performance bottlenecks and the system arrangement itself is constantly revisited to remove those identified issues. Matured generic software architectures adapt effectively to all the intended use cases while remaining within various resource constraints. For a general purpose operating system like Linux, the infrastructure for cache memory utilization is a good illustration of how various abstract software components can seamlessly coordinate with widely varying user requests.























{kind=link}